Vision-based pose estimation for construction robots




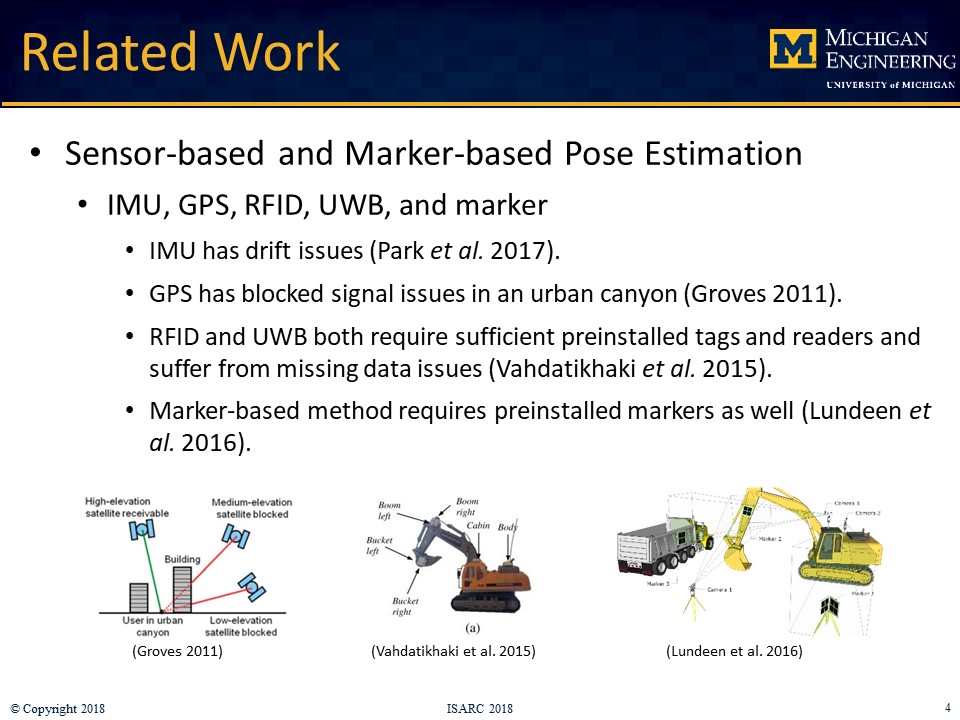



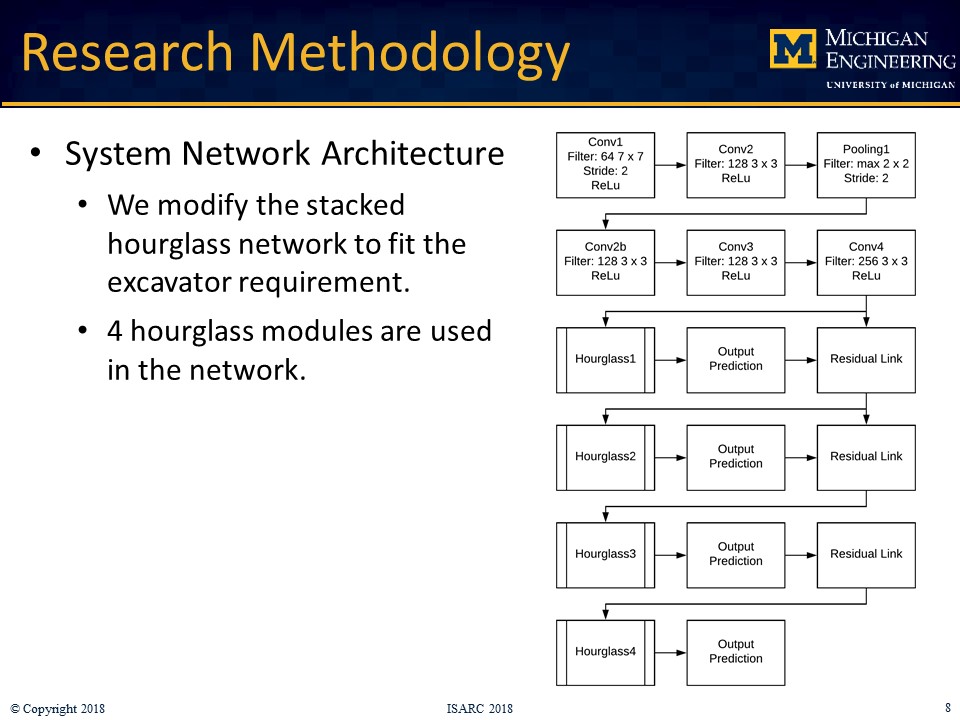
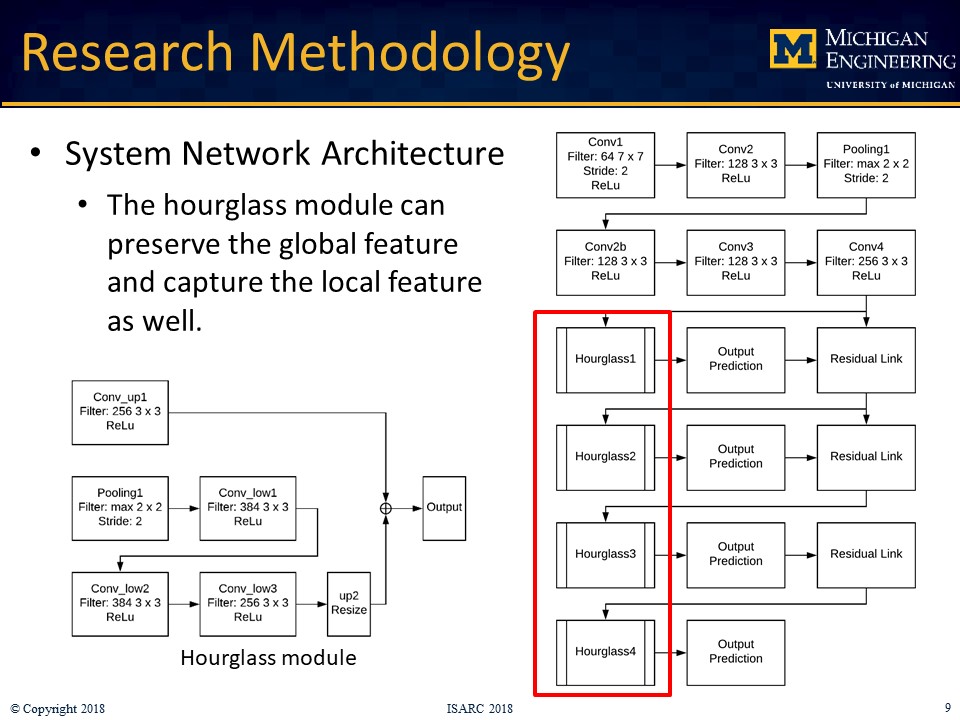
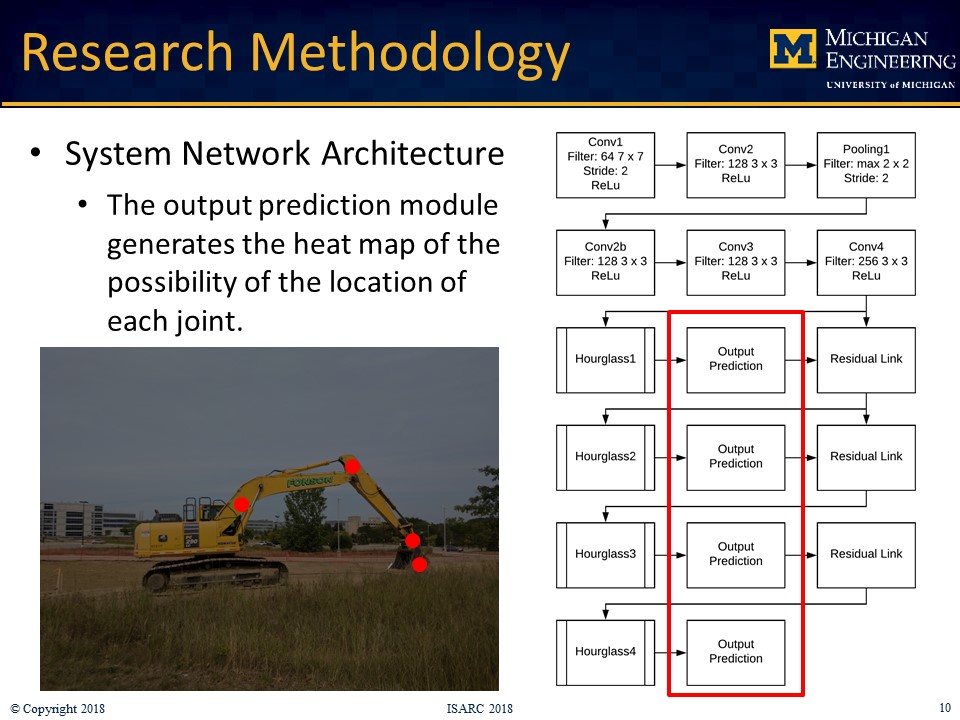










The prospect of human-robot collaborative work on construction sites introduces new workplace hazards that must be mitigated to ensure safety. Human workers working on tasks alongside construction robots must perceive the interaction to be safe in order to ensure team identification and trust. Detecting the robot pose in real-time is thus an essential requirement to inform the workers and to enable autonomous operation. Vision-based (marker-based, marker-less) and sensor-based are two of the primary methods for estimating robot pose. The marker-based and sensor-based methods require some additional preinstalled sensors or markers, whereas the marker-less method only requires an on-site camera system, which is common on today’s construction sites. This research developed a marker-less pose estimation system for on-site articulated construction robots, which is based on a deep convolutional network human pose estimation algorithm: stacked hourglass network. Both 2D and 3D pose are estimated. The system is trained with image datasets collected from a robotic excavator and annotations of excavator pose, as well as conventional excavators working on construction sites. A KUKA robot arm with a bucket mounted on the end-effector was used to represent the robotic excavator in the experiments. The marker-less 3D method was evaluated, and the results were compared with the sensor-based results and the robot’s ground truth pose. The results demonstrated that the marker-less 2D and 3D pose estimation methods are capable of performing proximity detection and object tracking on construction sites and can overcome the missing data issues encountered in the sensor-based method. However, the lower accuracy of the bucket pose estimation due to occlusion highlights the need for modifying the network and collecting additional datasets for training in future work.
Ci-Jyun Polar Liang
Assistant Professor (Jan 2024)
My research interests include Human-Robot Collaboration, Computer Vision, Reinforcement Learning, BIM, Digital Twins, and Extended Reality.
Publications
A vision-based marker-less pose estimation system for articulated construction robots


